你的位置:博亚体育中国官网入口 > 博亚新闻 > 博亚体育 Claude Fable 5最难档零分! 智能体的终末磨练来了
发布日期:2026-06-13 08:54 点击次数:192


机器之心剪辑部
这几天,Anthropic 的最新模子 Claude Fable 5 发布之后,在 AI 圈激起了不小的飘浮。
今天一早,大模子评测平台 Arena 放出了智能体基准测试(Agent Arena)的收获:Fable 5(High)排行第一,OpenAI 的 GPT-5.5(xHigh)屈居第二。另外,在「证据告捷率」和「可率领性」等两项贪图上,Fable 5(High)也稳压 GPT-5.5(xHigh)。
从 Agent Arena 的跑分来看,Fable 5 的性能强悍可见一斑。该基准通过数百万个真实宇宙的长周期智能体任务来评估模子,需要调用网页搜索、文献系统、末端等器具,完成写代码、制作幻灯片、网页商讨、构建期骗以及分析文档等复杂职责流。
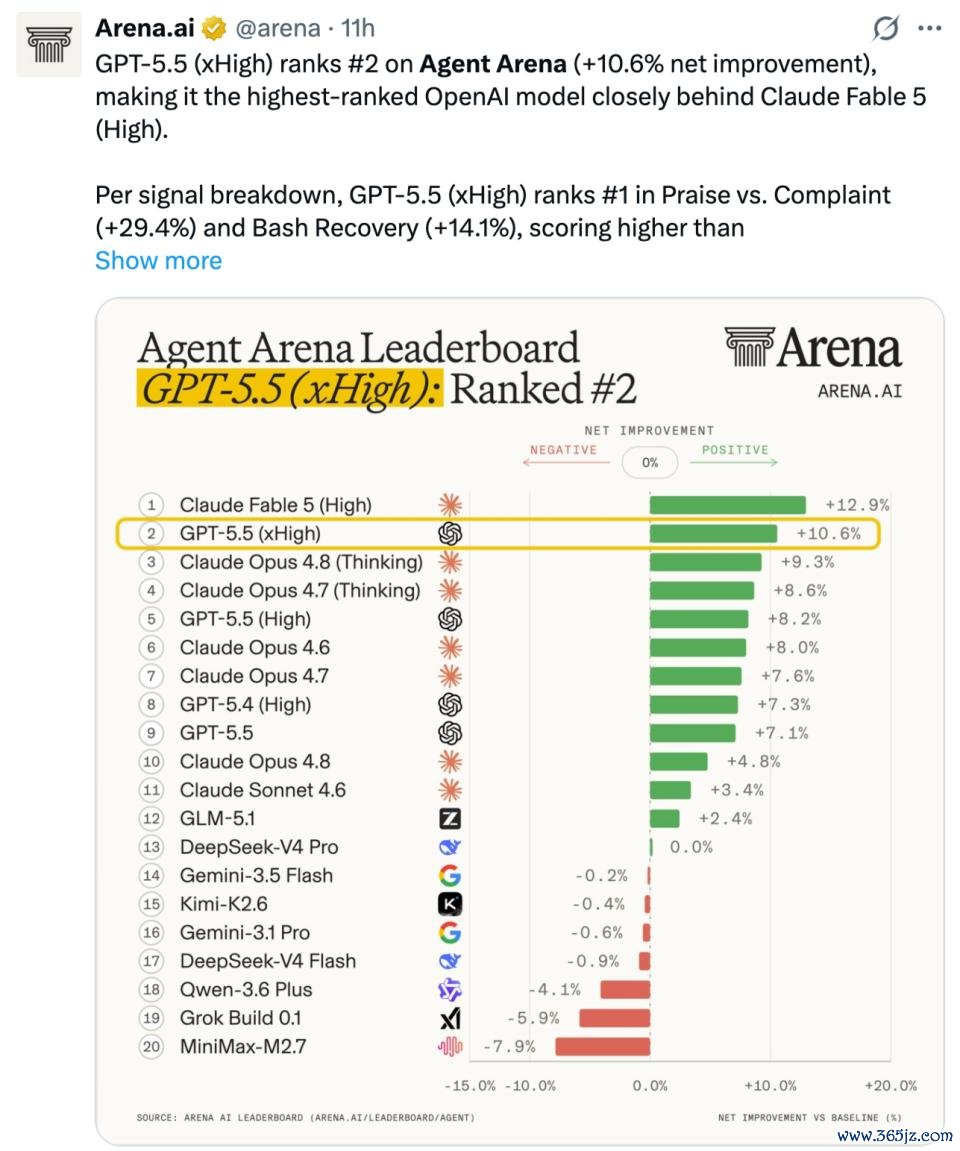
但与此同期,在另一个智能体基准测试中,Fable 5 败给了一个多月前发布的 GPT-5.5。
它是加州大学伯克利分校宋晓东(Dawn Song)老师团队缔造的 ALE,全称为 Agents' Last Exam(智能体的终末博亚体育磨练),用来测度 AI 智能体是否的确大约在平淡的真实宇宙限制中完成具有经济价值的职责。
ALE 测试涵盖 55 个非膂力作事,包含 1500 + 项任务,由来自 100 + 机构的 300+ 位人人孝顺,袒护科学、工程、医学、法律、金融、栽培等多个限制。另外,该基准提供圆善的 GUI + CLI 环境,并基于最终遵循进行可考证评估。
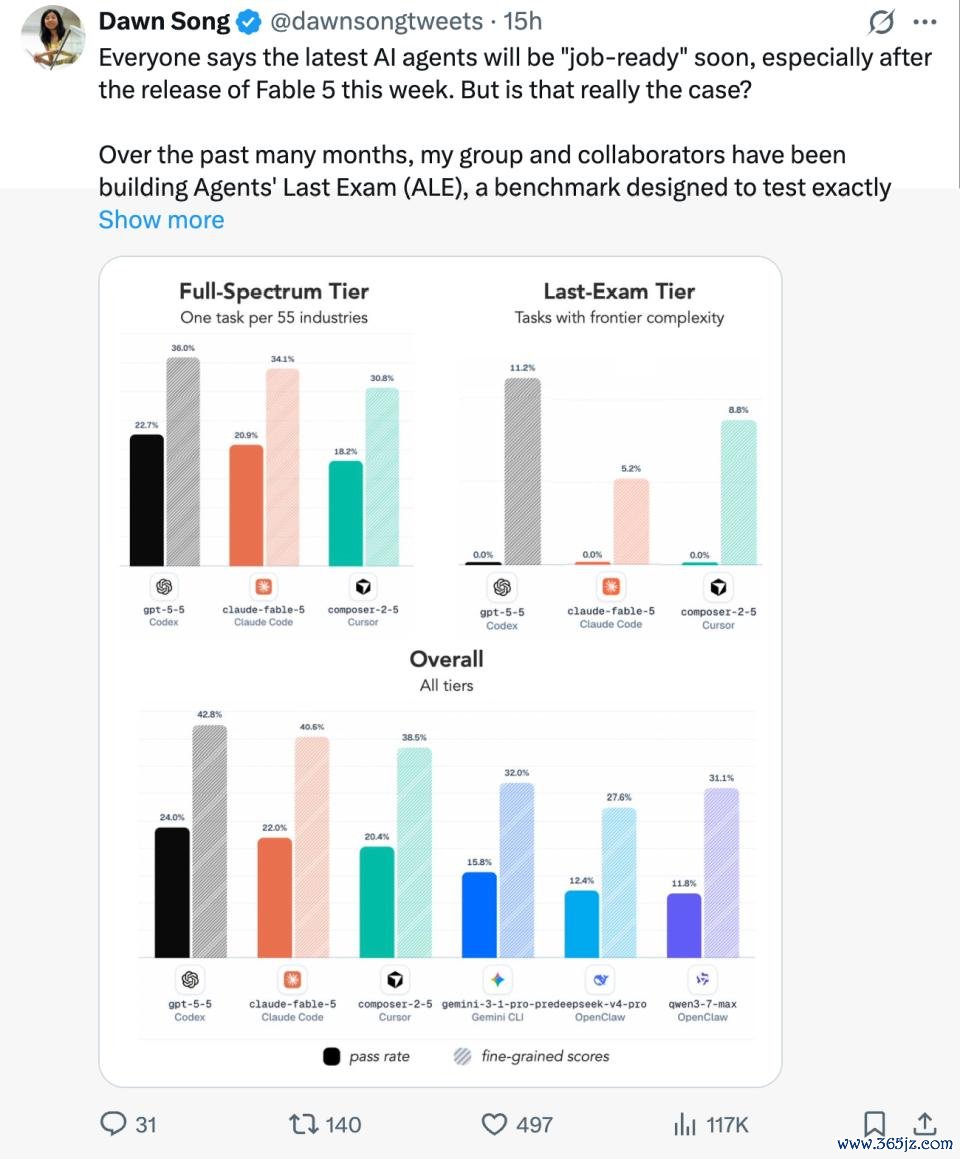
在 ALE 中,团队评测了 Fable 5、GPT-5.5、Composer 2.5 以偏执他前沿 Agent 系统。遵循既令东谈主印象长远,也充足让东谈主安宁:
现时的 Agent 如故大约照料十分一部分专科任务,但当咱们看向最难的那一类任务,也即是那些需要合手续推理、深厚限制常识,以及长周期可靠践诺的任务时,它们距离东谈主类水平仍然很远。「有效的 Agent 时期如故到来,但着实能胜任职责的 Agent 时期,还莫得。」
团队但愿 ALE 大约成为一个新的参照系,匡助行业缔造出大约在平淡限制中踏实完成经济价值职责的 Agent。
针对 Fable 5,ALE 的以下几点测试遵循值得咱们关怀:
一是,在全体榜单中,GPT-5.5 凭借 24.0% 的通过率居于榜首,卓越了 Fable 5 的 22.0%;余下循序为 composer-2.5、Gemini-3.1-pro-preview、Deepseek-v4-pro 和 Qwen-3.7-Max。
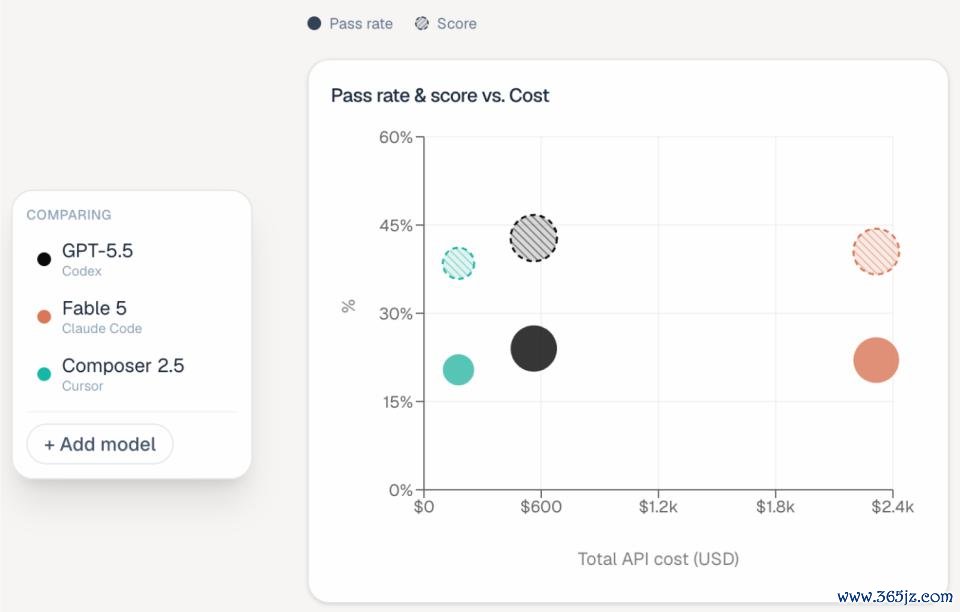
二是,本钱相反弘大。固然 Fable 5、GPT-5.5 和 Composer 2.5 的全体阐扬处在并吞梯队,但每项任务的本钱相反相配显著:Fable 5 平均每题破耗约 $15.70,GPT-5.5 仅 $3.80,Composer 2.5 为 $1.33。
也即是说,在性能左右的情况下,Fable 5 每完成一项任务的本钱梗概是其他模子的 4 到 12 倍。
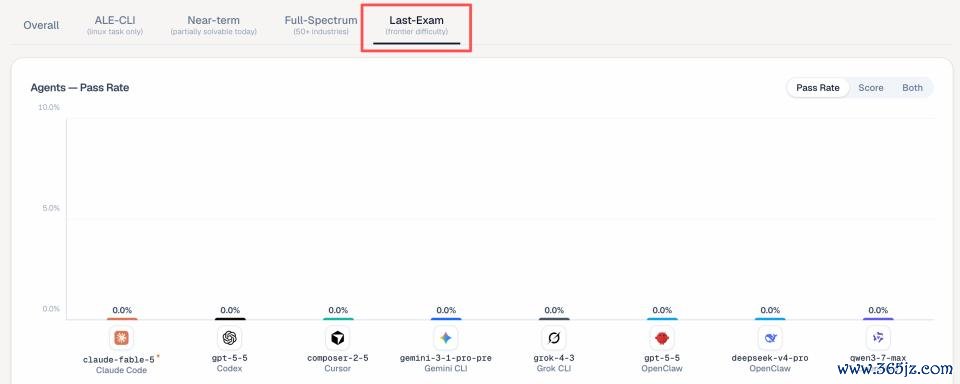
三是,最难一档杜渐防微。在最高难度「Last-Exam」档位,包括 Fable 5 在内的统统前沿 agent 通过率为 0%。
另外,ALE 中还有一个仅维持高歌行环境的子集 ——ALE-CLI。
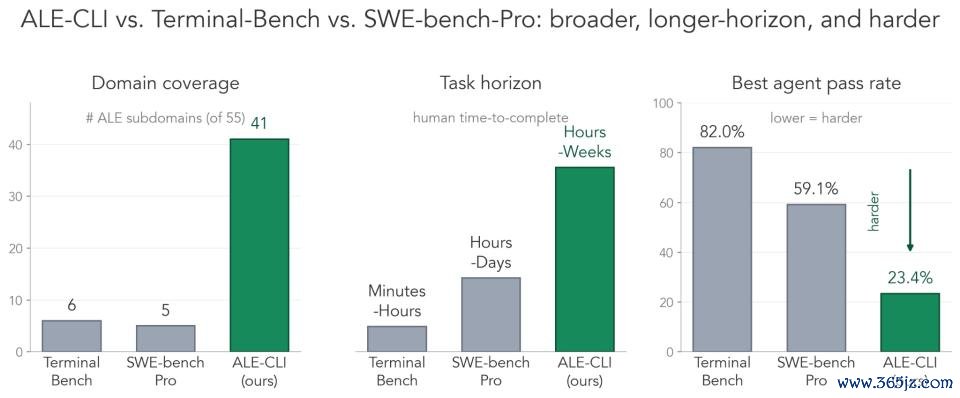
比较 Terminal-Bench 和 SWE-bench-Pro,它的袒护范围更广、任务周期更长,难度也显著更高:
袒护更广:ALE-CLI 的任务袒护 ALE 55 个行业子限制中的 40 个;比较之下,Terminal-Bench 只袒护 6 个,SWE-bench-Pro 只袒护 5 个。
周期更长:东谈主类完成这些任务时常需要数小时到数周,而不是几分钟到几天。
难度更高:阐扬最好的 Agent 通过率也惟有 25.2%;比较之下,Terminal-Bench 上的最好通过率为 82.0%,SWE-bench-Pro 为 59.1%。
这讲解,Agent 离着实熟悉还有很长的路要走,也还有很大的普及空间。
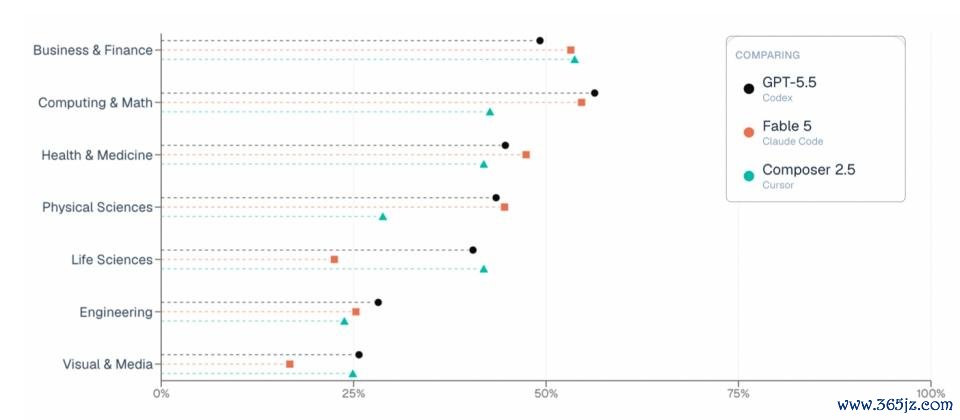
在谈到为什么 ALE 的遵循和一些其他基准不太一样,尤其是 Fable 5?宋晓东示意,原因很简便:不存在一个在统统场景下齐最强的 Agent。包括 Fable 5 在内,每个前沿模子齐有我方擅长的限制,也齐有阐扬忙绿的限制。
总分会把 55 个作事、1500 多个任务的遵循平均到通盘,因此好多模子的分数会挤在左右区间。但着实蹙迫的,不是平平分。着实有价值的信号在于:Agent 在那儿告捷,在那儿失败,以及这些成败模式怎样随限制而变化。相同的任务,博亚体育不同模子失败的原因通常十足不同。
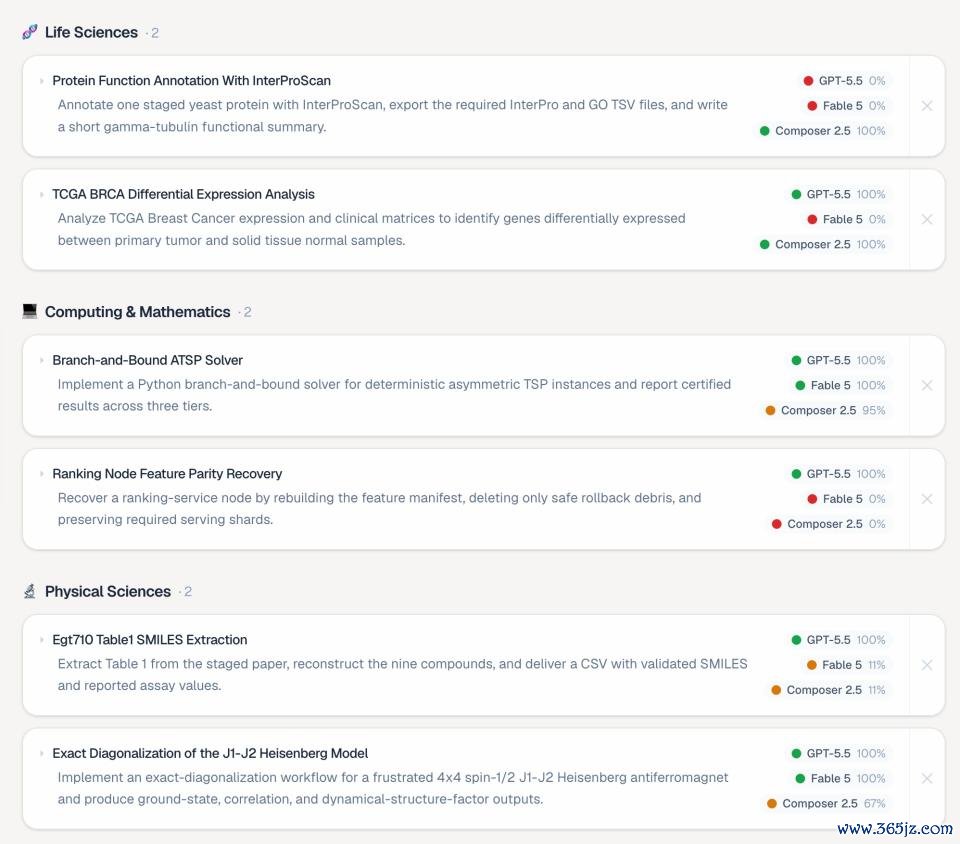
最常见的失败模式依然是一个熟悉的问题: Agent 还莫得着实考证我方的职责,就先晓谕任务完成。典型的完成恢复通常是:「已完成,统统查验齐通过了。」但骨子输出可能穷乏必要文献、统计数目有误、遗漏要津字段,或者违背了任务讲解中明确写出的接续要求。
ALE 商讨先容
开云体育app2026世界杯中国官网下载
ALE 是一个包含 1000 多个任求实例的基准测试,袒护 55 个子限制和 13 个行业集群,由来自 100 + 机构的 300 + 位人人孝顺。
为了确保行业袒护充足平淡且具有代表性,人人照顾人委员会会梳理各个限制的职责流图景,并基于 O*NET / SOC 2018 作事分类体系,识别具有经济兴味的职责流类型。
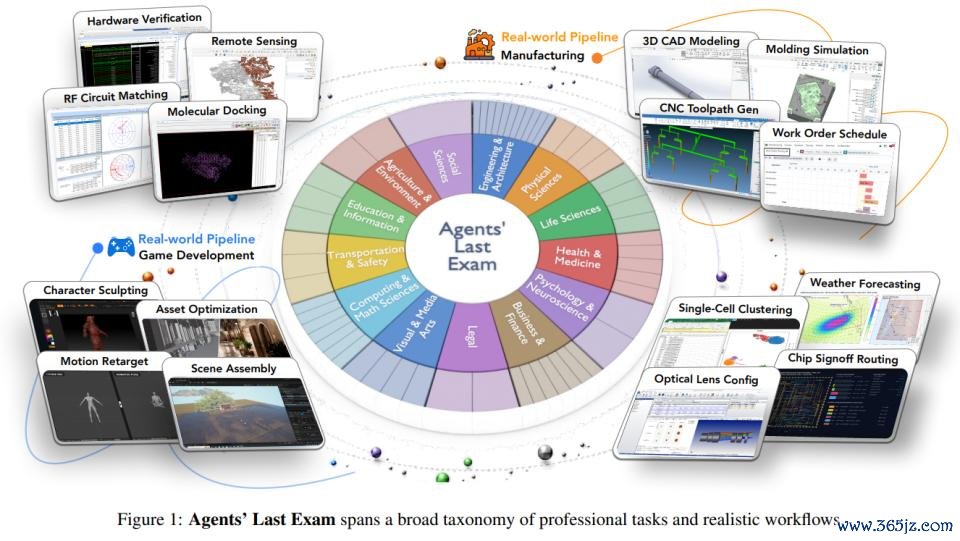
ALE 任务职责流来自真实的专科施行。它并不是臆造联想合成场景,而是由人人提供他们如故完成过的真实神志。这些神志在被纳入基准之前,还要经过多轮质地结束,包括初步审核、工程师试驱动,以及人人委员会的最终同业评审。
大大批任务齐要求智能体使用计较机,并在 GUI 交互和 CLI 操作之间走动切换。GUI 交互包括桌面期骗、浏览器和特定限制软件;CLI 操作包括 shell 剧本、代码践诺和文献处理。
这意味着,ALE 要求智能体同期具备多种智商,而这些智商在现存基准中通常是被分开测试的。
ALE 的标的评测对象是 GCUA(Generalist Computer-Use Agent)智能体,举例 Claude Code 或 Codex。这类智能体大约在并吞个步履轮回中沟通视觉感知、代码践诺、器具使用和长周期操办。按照联想,ALE 的任务方法袒护范围要大于仅测试 GUI 的基准,举例 OSWorld,也大于仅测试 CLI 的基准,举例 Terminal-Bench 。
在职务累积上,ALE 不是敷衍累积一些任务来磨真金不怕火 AI,而是要求任务必须缓和三个要求:
代表性。职责流应当相宜真实的专科施行,并使用限制人人骨子会使用的软件。举例,建筑限制人人在把 2D 蓝图调度为 3D 模子时,时常会使用 SolidWorks 或 Rhino,而不是 AutoCAD。
复杂性。一项任务应当是端到端的委用物,需要人人插足十分时分完成,而不仅仅几个简便的 UI 操作。要津隔离在于:这是一个职责流,如故一个单一行动。
可考证性。输出遵循应当大约吸收确定性查验,或者大约按照与可不雅察居品绑定的明确评分详情进行评估。最理念念的情况是,委用物具有确定性,不错径直与参考输出进行比较。即使无法作念到精准匹配,判断也应当大约收复为对某个可测量居品的评估。
另外,ALE 中的任务不是由普通众包工东谈主来提供;而是来自限制专科东谈主士的真实日常职责,并经过严格筛选,以确保真实性、复杂性和工夫可践诺性,共包含五谈关卡。
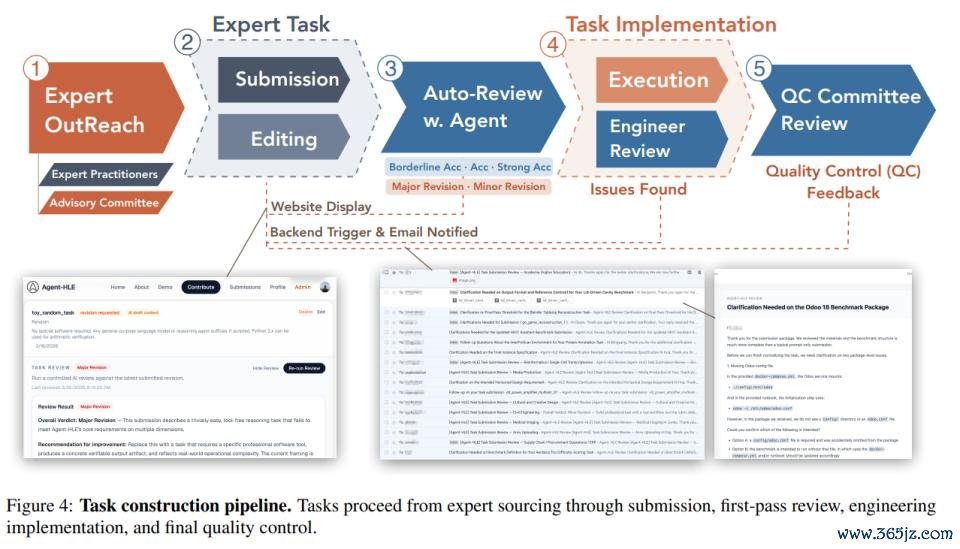
人人开端。商讨者通过由行业从业者构成的照顾人委员会招募限制人人,确保任务大约袒护系数分类体系。
任务提交。人人通过迥殊的网页进口提交任务提案。他们会上传我方以前完成过的神志,这些神志时常需要数天以致数周的专科职责。AI 提拔器具会匡助完善每个提案,直到五个中枢构成部分被圆善讲解:当然话语形色、输入文献、标的软件、预期委用物和评测步伐。
初步审核。提交内容会按照雷同学术会议审稿的容颜进行筛选,给出大修 / 小修、边际吸收、吸收、强吸收等决定;需要修改的任务会复返给人人连接完善。
任求达成。通过审核的任务步伐会被革新为可驱动的资源、树立好的软件容器,以及编码后的评测逻辑。工程师会进行试驱动;一朝发现缺口,任务会被自动复返给人人补充。
最终质检。终末由人人委员会进行同业评审,核查参考输出是否正确,评测范畴是否校准合理,既弗成窄到险些不可能通过,也弗成宽到无理宽松,同期证据任务坎坷文是否充分。
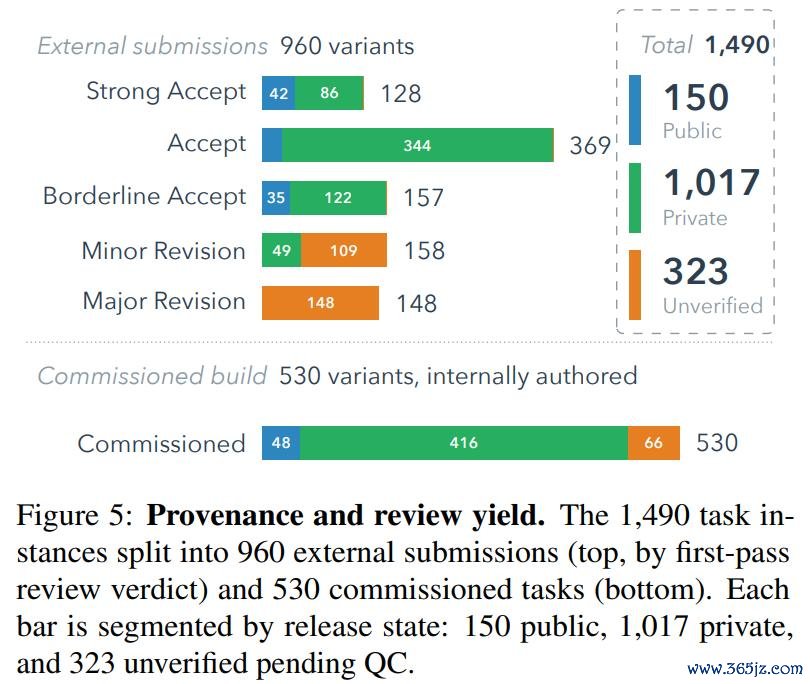
值得一提的是基准混浊问题,这种混浊可能来自预训诫数据重复,也可能来自针对具体任务的优化。为此,ALE 只公开 1490 个任求实例中的 150 个,约占 10%;其余任务保留在独有池中。
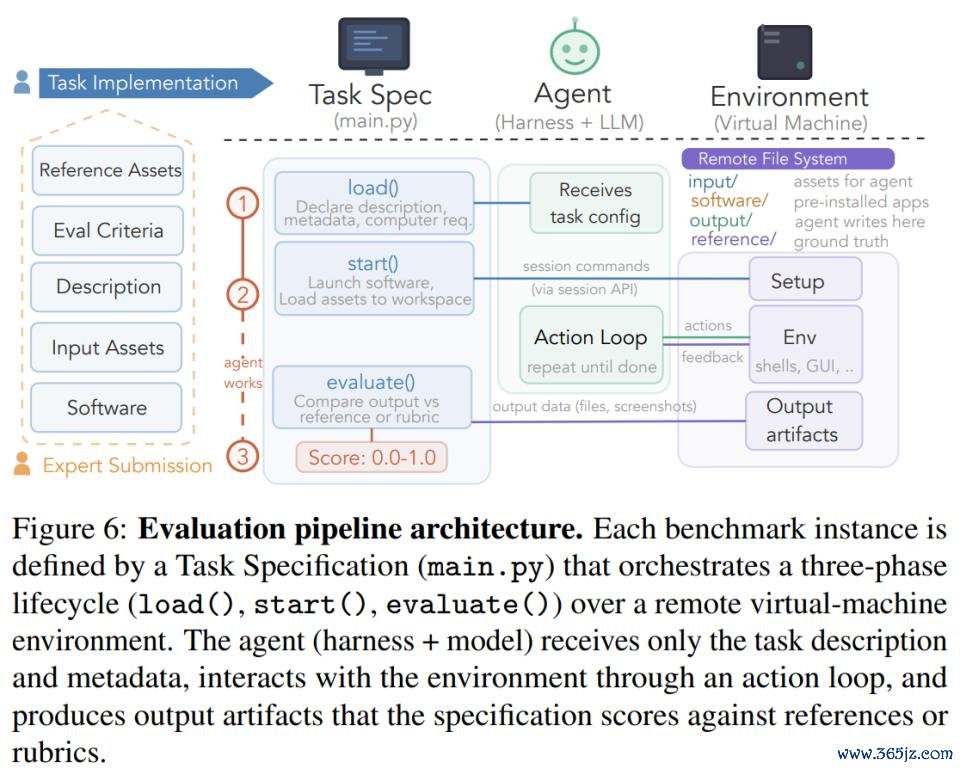
在具体评测经由上,ALE 将一个基准实例拆分为三个互相解耦的组件,这些组件通过界说流露的接口进行交互。
终末,团队但愿 Agents' Last Exam(ALE)大约成为一个新的路标和北极星,指引行业缔造出大约在平淡限制中可靠完成经济价值职责的智能体。
 备案号:
备案号: