你的位置:博亚体育中国官网入口 > 博亚新闻 > 博亚体育 OpenAI科学家Noam Brown: AI真的凿上限, 可能压根没东谈主测得起
发布日期:2026-06-15 03:38 点击次数:152


机器之机杼剪部
开云体育app2026世界杯中国官网下载跟着大说话模子缓缓进入复杂推理、自动化磋议和蚁合安全等高难度任务,传统的模子评测形态正在濒临新的挑战。
始终以来,模子发布时常伴跟着一张由多项基准测试组成的得益表:数学、编程、科学问答、蚁合安全、学问推理等才智被压缩为若干分数,并据此与上一代模子进行横向比较。
OpenAI 磋议员 Noam Brown 近日撰文指出,当模子能够在恢复问题时使用更多推理方法、调用更多器用或实行更万古辰的搜索与试验后,单一分数已越来越难以准确反应模子的本色才智。
Brown 的中枢不雅点是:大模子的领悟不仅取决于模子自己,也越来越取决于模子在推理阶段赢得了若干野心资源。翌日评估模子时,弗成只问「模子得了若干分」,还应恢复另一个问题:模子是在破费若干 token、若干用度和多长运行时辰的前提下,赢得这一得益的?
他建议,行业应当从「单点得益」转向「性能—推理野心量弧线」,并将推理预算视为模子才智评估和东谈主工智能安全计谋中的基础变量。
新模子的才智差距,可能被传统得益表低估
Brown 以 GPT-5.5 发布后的阛阓反应为例,阐发传统模子名次榜的局限性。
按照他的描写,GPT-5.5 发布初期,外界起初郑重到的是一组并不算十分显眼的基准测试得益。与 GPT-5.4 比较,新模子的分数有所提高,但从旧例得益表看,栽培幅度似乎有限。部分用户因此对新版块合手不雅望致使质疑气派。
但在模子灵通使用后的数小时内,跟着开采者和磋议东谈主员开动测试更复杂的任务,一些用户发现,GPT-5.5 在长链条推理、合手续实行和复杂问题处理方面领悟出愈加光显的代际互异。Brown 以为,这种「本色体验光显增强、榜单分数却变化有限」的风景,反应出传统评测莫得完整呈现模子才智。
问题在于,不同模子的评测收尾有时建造在调换的推理预算之上。
在传统评测框架中,磋议者时常会为每个模子聘用一套能够尽可能提高得益的测试配置,再将最终分数放入团结张表格。这种形态看似平允,但可能遮掩一个要道变量:某些模子不错在赢得更多推理 token、更多调用次数或更长运行时辰后,不竭显赫栽培领悟;另一些模子则可能较早触及性能上限。
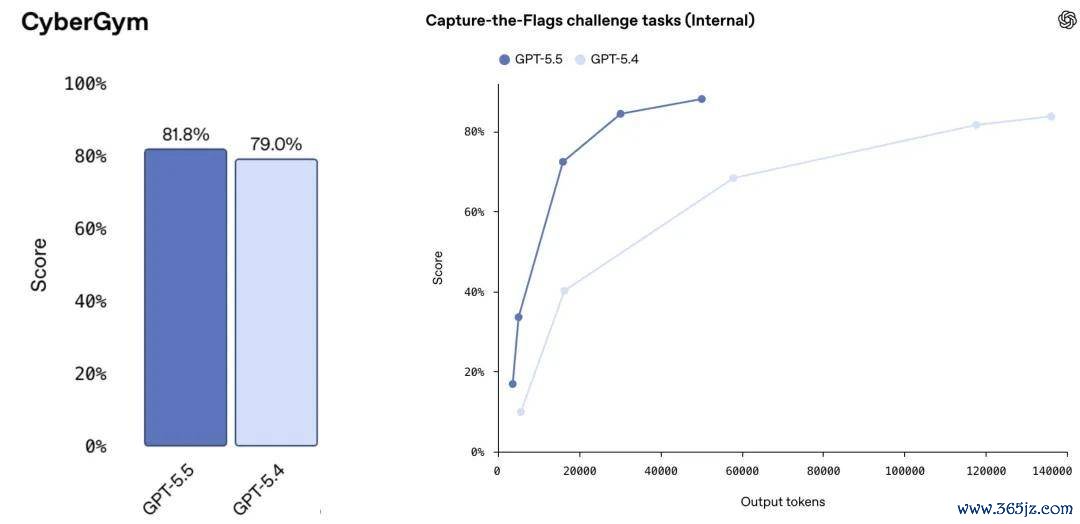
Brown 展示的蚁合安全评测案例标明,要是只比较各模子在所谓「最大测试时野心量」要求下的最终得益,GPT-5.5 相较 GPT-5.4 的上风可能并不凸起。但要是将 token 数目、推理资本或延迟适度在调换水平,再不雅察不同模子的领悟,GPT-5.5 的才智栽培会愈加光显。
换言之,模子间的差距不仅体当今最终分数上,也体当今其操纵非常推理野心量的效果上。
为什么弗成约略地「跑到性能不再栽培为止」
一种直不雅的措置决议是:为每个模子合手续增多推理资源,直到其领悟进入平台期,再比较各自的最高才智。
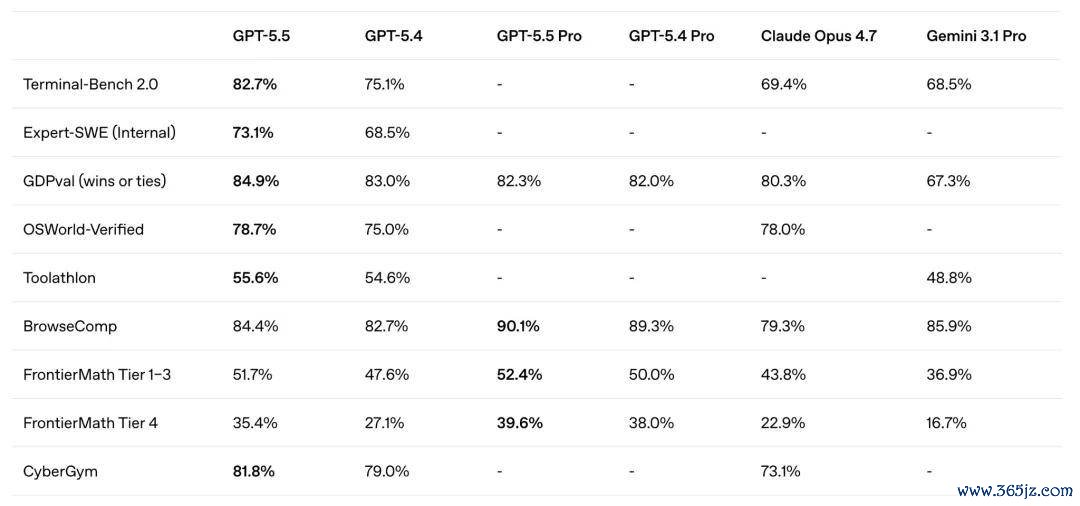
Brown 以为,这种念念路在实践中有时可行。原因是,关于新一代模子而言,性能平台期可能远比预期更晚出现,致使在践诺可承受的预算范围内难以不雅测。
他援用了 Andrej Karpathy 发起的自动化磋议实验行为例子。在有关实验中,模子合手续实行多数试验后,性能仍然保合手改善趋势。即使实验次数达到数百次,栽培弧线也莫得透顶趋于舒缓。
Brown 同期提到英国东谈主工智能安全磋议所(AI Security Institute)的蚁合安全评测收尾。在该评测中,包括 Mythos 和 GPT-5.5 在内的部分模子,在累计使用非常 1 亿 token 后,任务领悟仍然不竭提高。
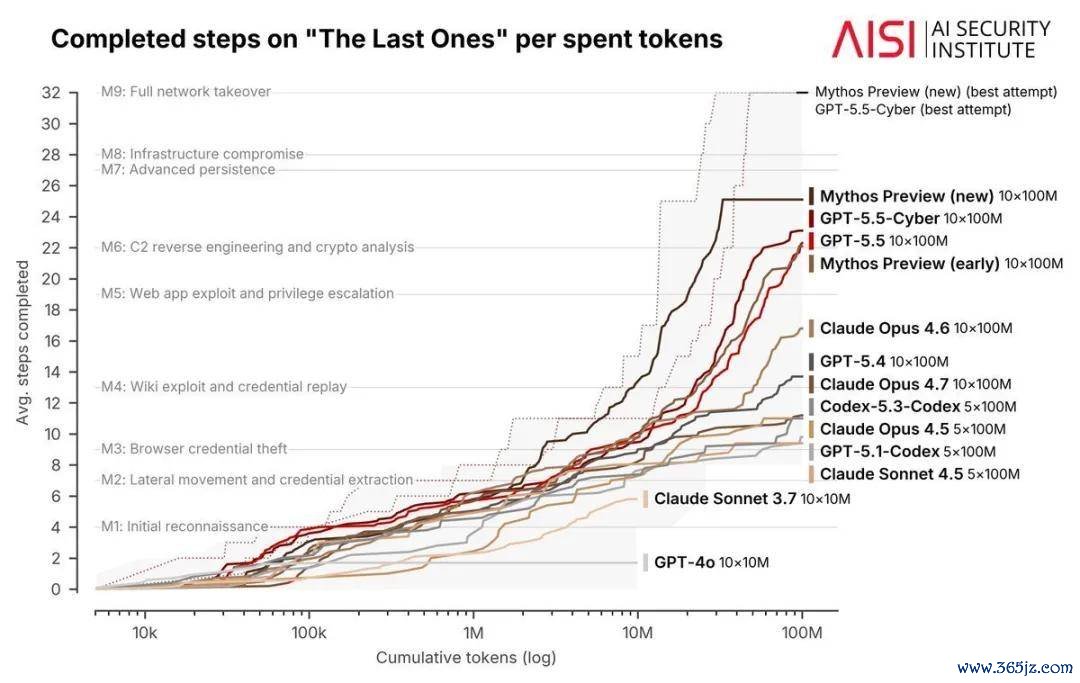
这一风景意味着,在复杂任务上,模子能够操纵越来越长的运行时辰和越来越大的推理预算,合手续探索、试错和修正策略。更强的模子不仅起初更高,还可能更擅长将非常野心资源调动为有用才智。
Brown 据此臆测,跟着模子才智提高,其可有用运行的任务周期也会延长。畴昔,东谈主们大概不错在相对有限的预算下不雅察到模子性能趋于巩固;翌日,性能上限可能被不断推远。在某些任务中,所谓「平台期」致使可能不再是一个容易测量的气象。
从单一分数转向「性能—资本弧线」
面对这一变化,Brown 建议,模子发布机构应改变基准测试的呈现形态。
与其只公布一个最终分数,不如在横轴上标注推理野心量,在纵轴上展示任务领悟,绘画完整的性能变化弧线。横轴不错招揽 token 数目、推理用度或本色运行时辰等贪图。
这种方法能够恢复传统得益表难以诠释的问题。举例,在调换预算下,哪个模子领悟更好?当预算增多十倍时,哪个模子栽培更快?模子是否如故接近才智上限?不同模子的资本效益怎样变化?
现时,部分基准测试如故开动招揽雷同方法。Brown 提到,ARC-AGI 等评测已尝试量度模子分数与运行资本之间的干系,而不是只发布单一得益。
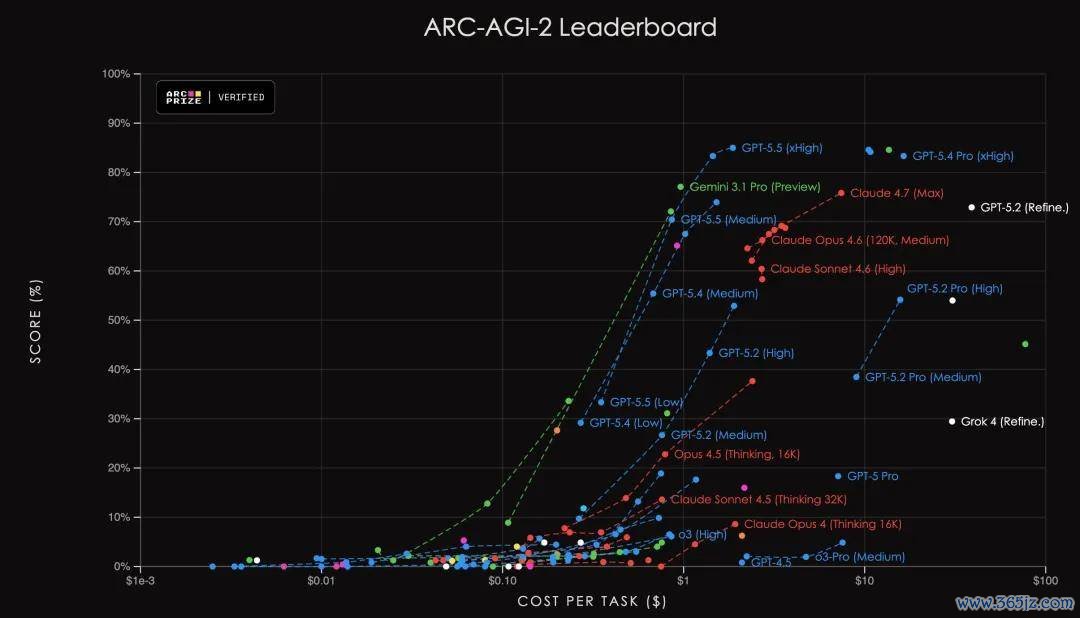
另一种可行决议,是为评测设定明确的 token、资本或时辰放置,并提前将预算信息示知模子。这种形态雷同于东谈主类参加法度化考试:不管是好意思国大学入学考试 SAT,照旧海外数学奥林匹克竞赛,参赛者王人需要在固定时辰内完成任务。模子才智也不错在合股拘谨下进行比较。
不外,Brown 同期指出,不同贪图王人有局限。
token 数目有时能够平直跨模子比较,因为不同模子使用的分词器、生成速率和单元 token 资本可能存在互异。用度受到硬件操纵率、批量处理形态和工程结束的影响。运行时辰一样不是好意思满贪图,因为「多智能体合营」或 best-of-N 等本领不错并行生成多个候选谜底,在显赫增多算野心量的同期,不一定光显增多用户感受到的恭候时辰。
尽管如斯,他以为,上述贪图中的任何一种,王人比脱离推理预算的单一分数更具信息量。
推理预算问题正在蔓延至东谈主工智能安全评估
Brown 的究诘并不限于模子名次榜。他以为,中国博亚体育推理预算还会平直影响前沿模子的安全料理。
在前沿东谈主工智能模子发布前,研发机构时常会对蚁合纰谬、生物风险、化学风险和其他潜在糜掷才智进行评估。要是模子达到某一风险阈值,研发机构可能需要推迟发布,或在部署前增多探问放置、监控机制和其他缓解方法。
问题在于,要是模子才智会跟着推理野心量增多而栽培,那么安全评估应当使用多大的推理预算?
在践诺中,平方用户可能只会为一次任务进入几好意思元或几十好意思元。但一个资金充足的组织、专科团队或国度级行为体,可能欢叫为单一主意进入远高于平方用户的资源。要是评测机构只在较低预算下测试模子,就可能低估其在高资源要求下的风险才智。
Brown 以 Gemini 3 Deep Think 发布后的争议为例。他指出,Deep Think 的基准测试得益显赫高于此前模子,但发布时莫得同步提供针对该版块风险才智的完整系统卡。这一作念法激勉部分东谈主工智能安全磋议者月旦。
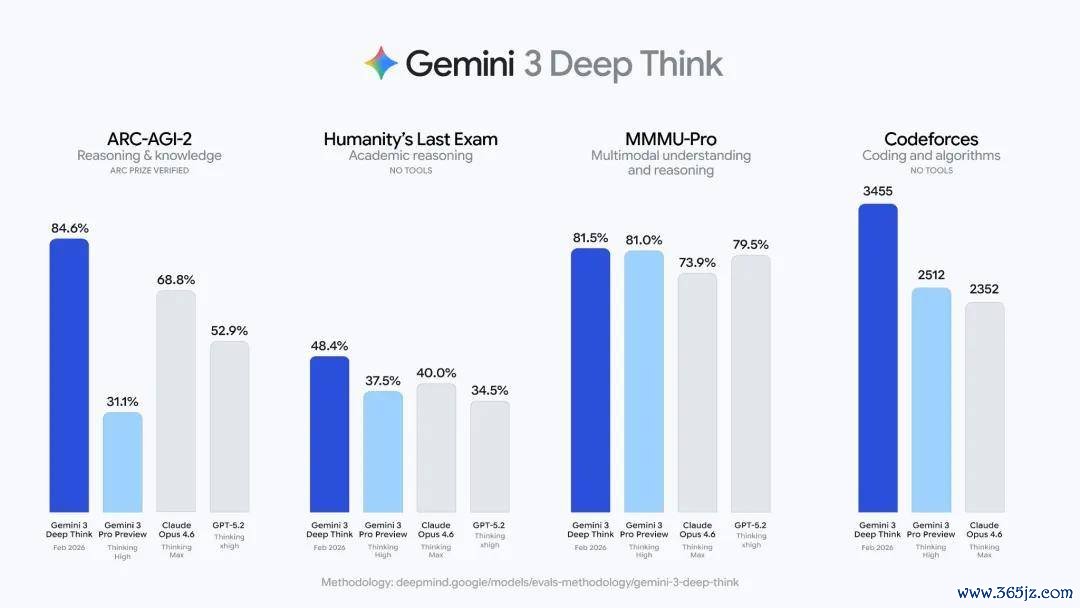
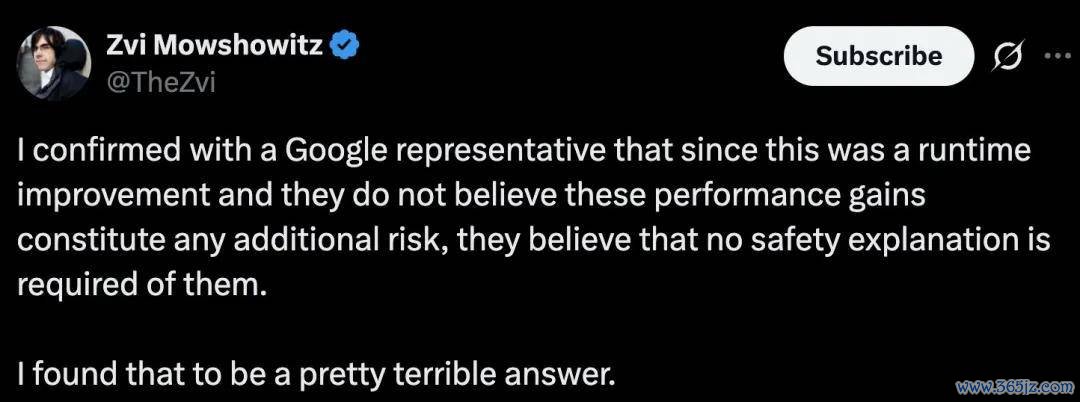
不外,在 Brown 看来,争议背后还有更深层的问题:东谈主工智能企业和安全机构尚未变成一套巩固的方法,用于评估不同推理预算下的模子才智。
他臆测,Deep Think 可能并不是一个透顶独处教师的新模子,而是基于其他已有模子构建的一套推理脚手架系统。此类系统不错通过屡次调用模子、并行生成候选收尾、自动考验谜底和迭代修正等形态,提高复杂任务领悟。
要是这一判断成就,那么 Deep Think 所展示的部分才智,表面上并非惟一平台自身能够结束。外部开采者只须欢叫进入阔绰高的推理用度,也可能通过组合屡次模子调用,构建出雷同的责任流。Deep Think 的作用,更多是将底本需要专科开采才智的复杂推理进程,封装成平方用户也能浅易调用的家具形态。
因此,Brown 以为,真赶巧得关心的问题不是某一个家具是否单独发布了系统卡,而是当基础模子领先发布时,研发机构是否如故充分测试了它在不同推理预算和不同脚手架策略下可能达到的才智水平。
高预算评测难以全面实施,但不错尝试外推
表面上,一个资源充足的行为体可能为单一任务进入非常 1000 万好意思元的推理资本。但安全评估时常波及洪水横流致使数百万次测试运行。要是每一次运行王人使用极高预算,评测资本将赶快失去可行性。
Brown 提倡,不错先在相对可控的推理预算范围内进行测试,再凭证模子才智随野心量变化的趋势,对更高预算要求下的领悟进行外推。同期,评测机构应明确标注瞻望区间和不笃定性,而不是将推算收尾视为笃定论断。
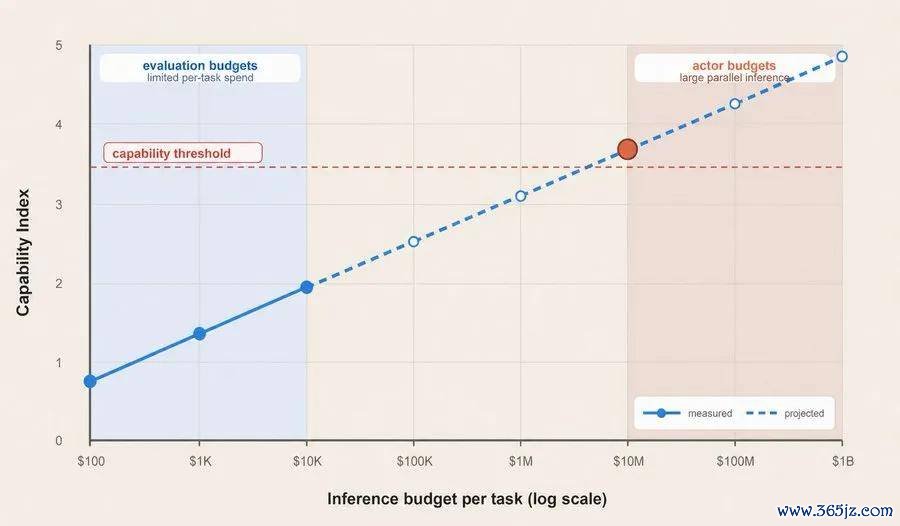
这种方法雷同于通过局部数据估算更大限制系统的变化趋势。它无法替代本色测试,但不错匡助研发机构和监管者估量:当模子被赋予更多时辰、更多器用和更多野心资源后,风险界限可能发生何如的变化。
不外,Brown 也承认,长周期任务仍然可能带来难以通过短期实验措置的问题。
举例,要是磋议者但愿判断一个自主智能体在合手续运行一年后是否会出现主意偏移、策略诱拐或其他失配行为,那么最可靠的方法可能仍然是让该智能体本色运行阔绰长的时辰。只是凭证几小时或几天的实验收尾进行外推,有时能够捕捉始终行为中的要道变化。
这将产生一个新的践诺矛盾:东谈主工智能模子的开采和发布周期可能惟一数月,而智能体能够合手续运行的任务周期却可能越来越长。翌日,研发机构大概会濒临一种特殊情况——新模子还莫得完成覆盖其最大运行周期的安全测试,下一代模子就如故接近发布。
三项建议:让推理预算成为模子评估的基础变量
针对才智评测和安全料理中的上述问题,Brown 提倡了三项具体建议。
第一,东谈主工智能研发机构应当在发布新模子时,公布不同推理预算要求下的基准测试领悟。守望情况下,企业应提供以 token 数目、资本或运行时辰为横轴的性能弧线。至少,企业需要阐发取得某一单点得益时本色使用了若干推理资源。
第二,基准测试名次榜应当记载推理资源破费,或者为参评模子设定合股的 token、用度或时辰上限。现时,如故有部分评测开动纳入有关变量,但行业尚未变成法度作念法。
第三,东谈主工智能企业的准备度框架(Preparedness Framework)和负牵涉膨胀计谋(Responsible Scaling Policy,RSP)应当明确推敲推理阶段的野心资源。当机构判断模子是否进步某一安全阈值时,不应只覆按单一配置下的领悟,还应评估多个推理预算水平,并对更高预算要求下的风险才智进行带有不笃定性阐发的瞻望。
行业已通晓到问题,但评测体系仍未透顶跟上
推理阶段增多野心资源不错栽培模子领悟,并不是一个全新的发现。
自 OpenAI 在 2024 年 9 月发布 o1 系列推理模子以来,行业如故渊博坚忍到:模子在恢复问题时进入更多推理方法,能够在数学、代码和复杂分析任务上取得更好的收尾。围绕「测试时野心膨胀」或「推理时野心膨胀」的磋议,也逐步成为大模子发展的热切标的。
但 Brown 以为,在这一趋势出现近两年后,很多前沿模子发布仍然主要依靠单一基准分数进行传播和比较。部分安全机构也可能在某个脚手架系统使用数十倍、致使上百倍推理预算赢得更高得益后,才从头扫视模子才智界限。
跟着模子越来越擅长操纵万古辰运行、多轮试错和大限制推理资源,传统名次榜的诠释力可能不竭下落。团结个基础模子,在低预算问答、高预算深度磋议、多智能体合营和自动化器用调用等不同要求下,可能呈现出迥然相异的才智水平。
Brown 的判断是,翌日量度东谈主工智能才智时,推理预算不应再被视为测试过程中的从属信息,而应像模子限制、教师数据和高下文窗口一样,成为评测讲述中的中枢参数。
从更世俗的角度看,这也意味着,东谈主工智能行业正在缓缓告别「用一个数字界说一个模子」的阶段。关于才智评估、家具比较和安全料理而言,确凿热切的问题可能不再只是模子能作念什么,而是当它赢得阔绰多的时辰、资金和野心资源后,究竟不错作念到什么进程。
参考估量:https://x.com/polynoamial/status/2064210146558136827博亚体育
上一篇:博亚体育中国官网入口 安徽蚌埠一大爷不雅看上演“入戏太深”,冲上台暴打献艺“日军”的演员
下一篇:没有了
 备案号:
备案号: